

If you run a PMO, you’ve fought the padded estimates battle. You’ve sat in the room where a six-week task gets quoted at ten, everyone knows it, and nobody says a word. This week, I snagged Norman Patnode for an interview about why and how this happens: if we all know padding is a problem, why can’t we fix it?
I met Norman Patnode on LinkedIn last year, and my reading list has been bursting to full since. Every few weeks, he sends me something to read…and it’s always fantastic. Many of the pieces he’s sent (and his commentary) have changed or evolved my thinking about long-held opinions—which is more or less the point of Big Dumb Questions.
If you look Norman up on LinkedIn, you’ll see he’s a Principal Consultant at ProChain Solutions—his whole world is helping project teams figure out how to model work so estimates actually mean something. So when Norman said yes to sitting down and digging into this one, I jumped at the chance.
Here’s our conversation.
You are an expert at helping clients build accurate “project models” of the work and dependencies, enabling pretty sophisticated scenario modeling and forecasting. Given the breadth of your experience building these models, why do you think teams still struggle with accurately (and honestly) estimating how long work will take?
Norman: Let’s start with the question: Why are we building a schedule? What do we need it to do for us?
Two common answers:
We want to know when the project will be completed, or when we’ll complete an intermediate milestone.
We need to know what work is required to achieve the desired outcome, so we can map out the best path forward.
Knowing the purpose of the schedule helps you build a “useful” schedule. But regardless of the purpose, I recommend building a dependency-based model of the work, and if resources are a constraint, also model the constrained resources. This will allow you to create a schedule that’s much more useful than a list of tasks and due dates.
Okay, let’s assume we want a schedule that does both #1 and #2. It needs to tell us when the work will be completed, but we also want to understand the work required. How accurate would the schedule need to be?
Norman: Okay, let’s talk about accuracy, and then we can talk about how to estimate durations in a realistic way.
In building a model of the workflows, how accurate does it need to be?
The short answer is: enough to be useful, and no more.
Increasing accuracy usually means adding detail, and adding detail comes with costs – more time to create it, and more time to update and maintain it.
Think about making a road trip with one of those old-fashioned fold-up paper maps. Let’s say we’re driving from Chicago to LA. To have a perfectly accurate map, it would have to be life-sized. Can you imagine trying to unfold and use that in the car as you’re driving?
Now, let’s take that thought and carry it into building a project model. How much detail do we need? Focus on building a “useful” model, and avoid the trap (and costs) of adding more and more detail to make the model more “accurate” (than needed).
So help us understand: how can you estimate durations with credibility if you’ve decided not to include robust detail?
Norman: I hear you, and that’s the conundrum. The answer is to learn to think in ranges.
For a given task, regardless of the level of detail, determine the range of likely completion.
Answering these two questions is one way to do that:
- You’d be surprised if you finish this task in less than ____ (fill in the blank) ____?
- You’d be surprised if this task takes longer than ____ (fill in the blank) ____?
Let’s say the task is to develop a new protocol. With these questions, our duration might be 3-7 weeks. Using duration ranges allows us to capture the uncertainty in how we’ll do the work, the variability in the work itself, and the risks we might encounter.
Asking these two questions also opens the door to conversations such as:
- What might we be able to do to finish this task in less than 3 weeks?
- What are the things that might cause this task to take 7 weeks? As a team, what could we do to mitigate those?
Do you see how these conversations can help a team increase accuracy without necessarily having to add more detail?
So walk us through how you would use these questions to model when a project will complete.
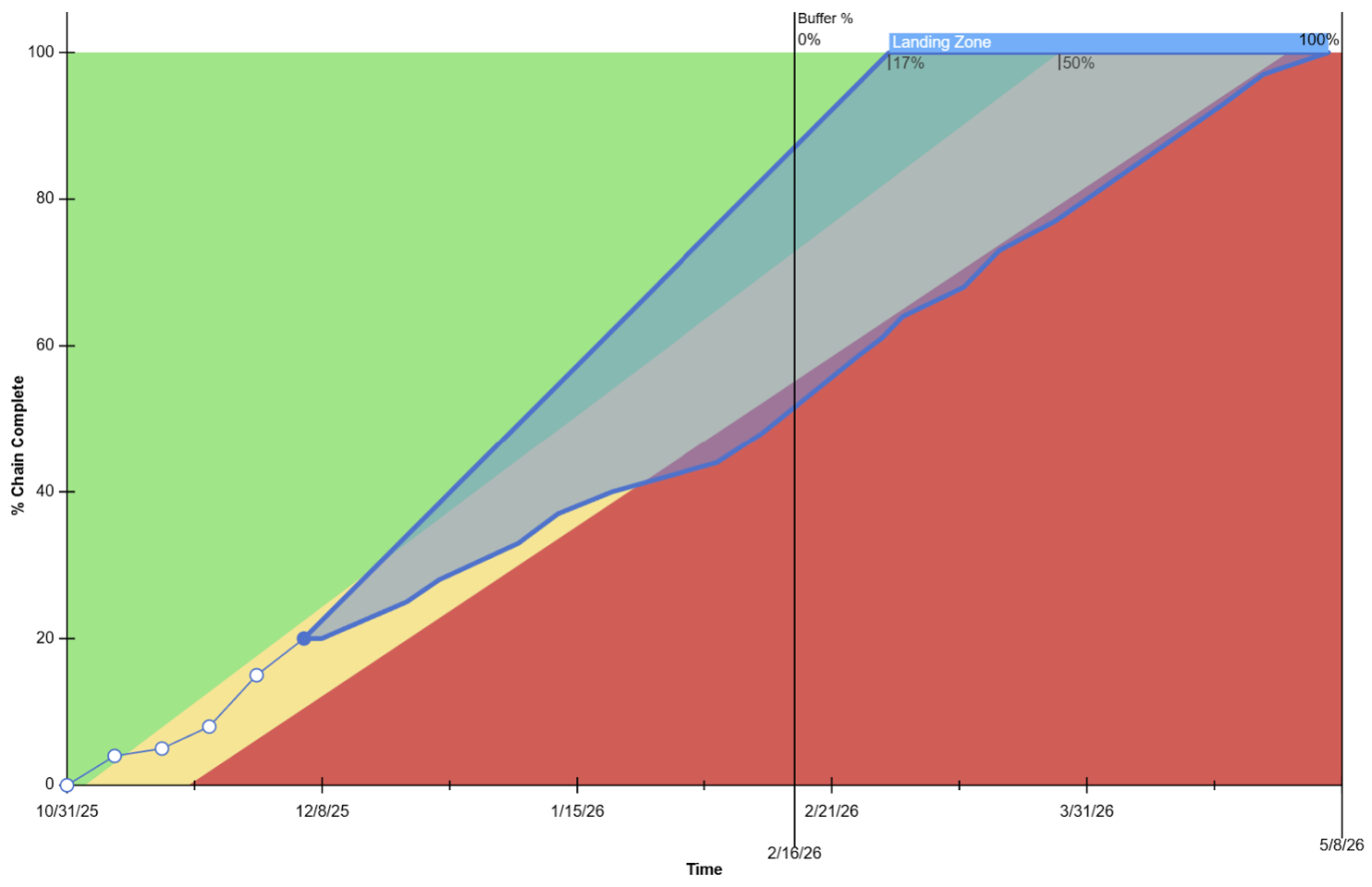
If you’re building a schedule to answer purpose question 1 (when will we complete), we can schedule using the short side of the durations…to show what’s possible (although highly unlikely), and use our model of the variability/uncertainty/risks to calculate a “landing zone” showing the range of likely completion.
My recommendation is to use the end of that landing zone as the commit date for completion. During execution, if you continue to use ranges when updating tasks (e.g., I now have 2-5 weeks remaining on the protocol task), you can continue to show the range of expected completions.
Here’s an example of what that dashboard could look like: It’s called a “fever chart.” You can also check out this video to see how it works: https://vimeo.com/715720878/88a1cd4029
(Transparency Disclaimer: This dashboard and video are from my company’s software, Fusion Online, which enables project teams to do this kind of modeling more easily.)
And what about if you’re building a model to answer the question: “What work is needed to achieve the outcome?”
Norman: So here’s an interesting point: If you’re building a schedule to answer purpose question 2 (how do we align on the best path forward), oftentimes the “accuracy” of the durations doesn’t even matter.
Let me explain.
Suppose all the durations are 75-100% too big. They’re all padded. If the team has mapped out the logical dependencies of the workflows (by identifying each task’s predecessors and successors), even with these padded tasks, they can still use their model to align on where to focus and how to move forward.
What’s the longest chain of tasks to the endpoint? What’s the task at the front of that chain? That’s the #1 priority task for the team. So how can we avoid delays on that task? What else can we do to speed its completion?
But it’s not enough to just look at the longest chain. What’s the second-longest chain? The task at the front of that chain…that’s the team’s #2 priority. And the third longest chain? And the fourth? So even if all the durations are padded, the team can still use their model to identify and set priorities…as a team.
Now, by tracking their progress in the fever chart, in 3-6 weeks, it will become very obvious (to the team and their leadership) that the durations are padded…because the landing zone will show a likely completion date well before the commitment date.
(And in my experience, at that point the team will be ready and willing to correct their schedule.)
So what do you think keeps more teams from using this approach? Lack of knowledge? Poor tools? Something else?
I’ve been using this approach with teams for decades. It produces outstanding results, and it’s not even that hard…so your question is an interesting one.
In my experience, there are several reasons, all intertwined. But these are the first two to address:
- You have to build a dependency-based model…ideally, as a team.
- You have to shift from working to task due dates to working to task priorities.
Let’s start with the first item. What do you think keeps teams from taking the time to thoroughly identify dependencies? (And, how thorough is enough?)
Norman: While time is always an issue, it’s actually not the real obstacle…it’s the mindshift required. It’s changing the rules. It’s changing how we think about our work.
It’s interesting, because every team I’ve taken through this process always starts with, “Wait! You want us to spend how many hours…planning?!” But then once we get into it, that same team always says, “Wow! We should do this for all of our projects.” The value is quick, and it’s obvious.
But let me go back to “changing the rules.” If you’re used to creating a list of tasks, and negotiating a due date for each…modeling the workflows as a team is very different indeed.
It starts with how you name a task. Rather than a one or two-word description of an event, task names need to describe the work (not the end state of being done with the work) and should include a verb.
For example, instead of “Test,” the task name might be “Conduct environmental testing on component A3.” This might sound trivial, but without a clear, common understanding of what work is in a task (or not in a task), how can you credibly determine what’s needed before you can start that work?
As the team does this modeling work, you’ll hear them ask questions:
“Do we really need the final version of the circuit board before we can conduct round 1 integration testing? Could we use the breadboard version?”
They will ask questions, solve problems, and make decisions much earlier than would’ve happened before. That’s valuable. And I see it happen every time. It’s a different way of thinking and a different way of working.
And here’s another key difference: If your schedule is just a list of tasks and dates, those dates are an input to your planning process. But when you build a dependency-based model, where you’ve mapped out the workflows (Task A → Task B → Task C), dates become an output, rather than an input. Again, a different way of thinking, a different way of working.
Okay, and now the second item: What does it mean to shift from working to due dates vs. working to task priorities?
Norman: If you can imagine a team using a schedule with no dates, then you’ve made the mind shift.
Let me explain how this works using the screen capture below (again from Fusion Online, my company’s software). Look at the data in the Criticality column, along with the dependency mapping shown in the Gantt chart.
The critical tasks are the longest chain, so the two tasks at the front of that chain are the team’s highest priority. The chain with 1 day of criticality is the second-longest chain, so the task at the front of that chain is the next highest priority. By using their model, the team can quickly align on where to apply focused effort.
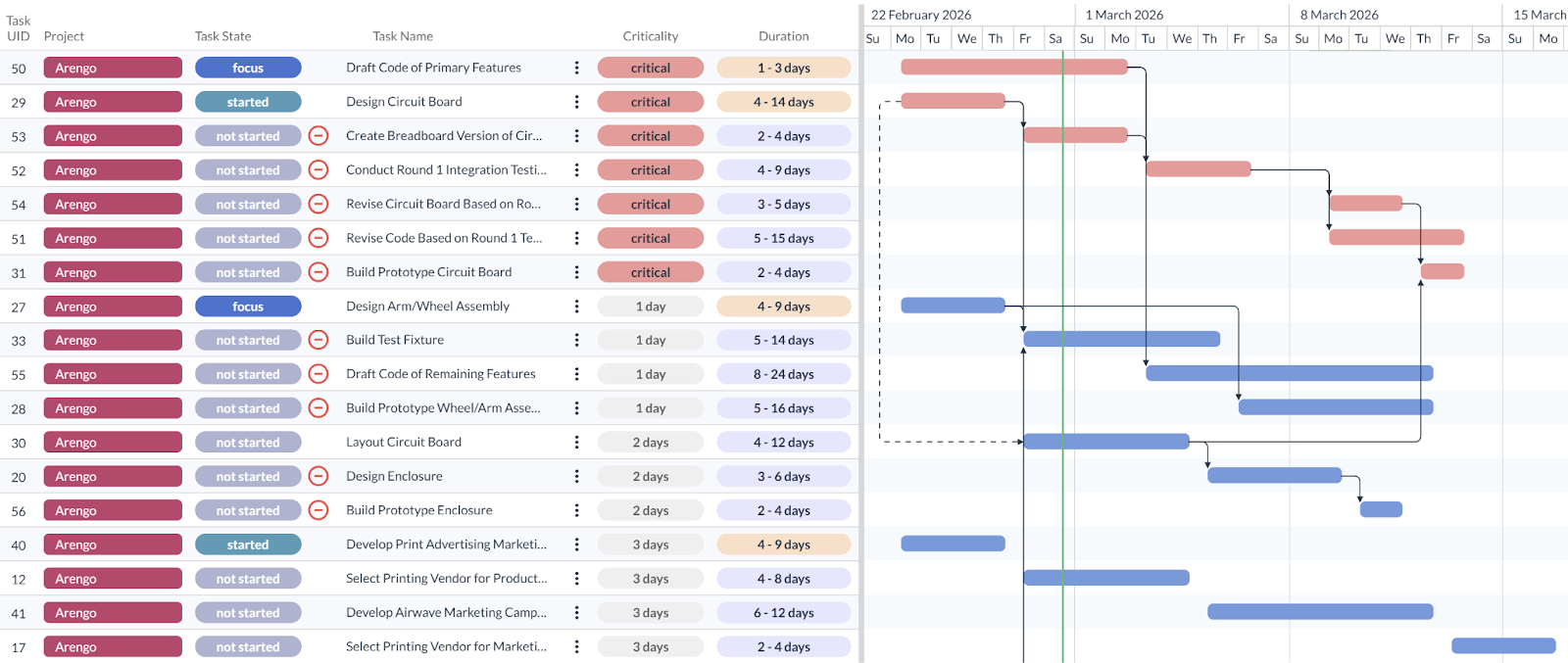
And if you haven’t made the mindshift yet, rest assured that if I moved the divider bar to the right, we could see dates…indeed we could see ranges of dates, for when tasks are expected to start and finish.
So what blocks teams from working to task priorities, rather than to task due dates?
Norman: Well, as Eli Goldratt was fond of saying, “Tell me how you measure me, and I’ll tell you how I behave.”
But let’s explore the question behind your question: If we’re not going to hold people accountable for meeting their due dates, what should we hold them accountable for?
- Are they working on their #1 priority task?
- Are they applying focused effort to finish it with quality and speed?
- Do they ask for help when they’re blocked by an obstacle they can’t clear themselves?
- Do they help the team identify and capture opportunities to accelerate project completion?
For many people, this is definitely a mindshift. I’m thinking about the CEO of a company I was working with, who looked at me and said, “This is hard. I know how to hold my people to dates, and while I see the value in this change, I’m struggling.” Indeed, a different way of thinking, a different way of working.
So let’s go all the way back to the original question: why do you think teams still struggle with accurately (and honestly) estimating how long work will take?
Norman: Well, we’ve covered a lot…and I hope it’s helpful.
To summarize, let me pose a question:
Without a useful understanding of the workflows, including both logical and resource dependencies in those workflows, and without a way to explicitly address the variability/uncertainty/risk in those workflows…and if my duration estimates will be turned into due dates I’m expected to hit…how can I realistically be expected to provide a better estimate?
Said another way, this is not a problem of team members making poor estimates, it’s a problem resulting from the system team members find themselves in.
If you want different results, you need to change the rules and play a different game.